How to get Generative AI working in your business
7 May 2024

Once upon a time, we had to interact with computers through complex binary code. However, we soon developed more human readable programming languages like, for example, Python. With the rise of generative AI (genAI), powered by Large Language Models (LLM), we have taken another step. We can now interact with our computer through natural language.
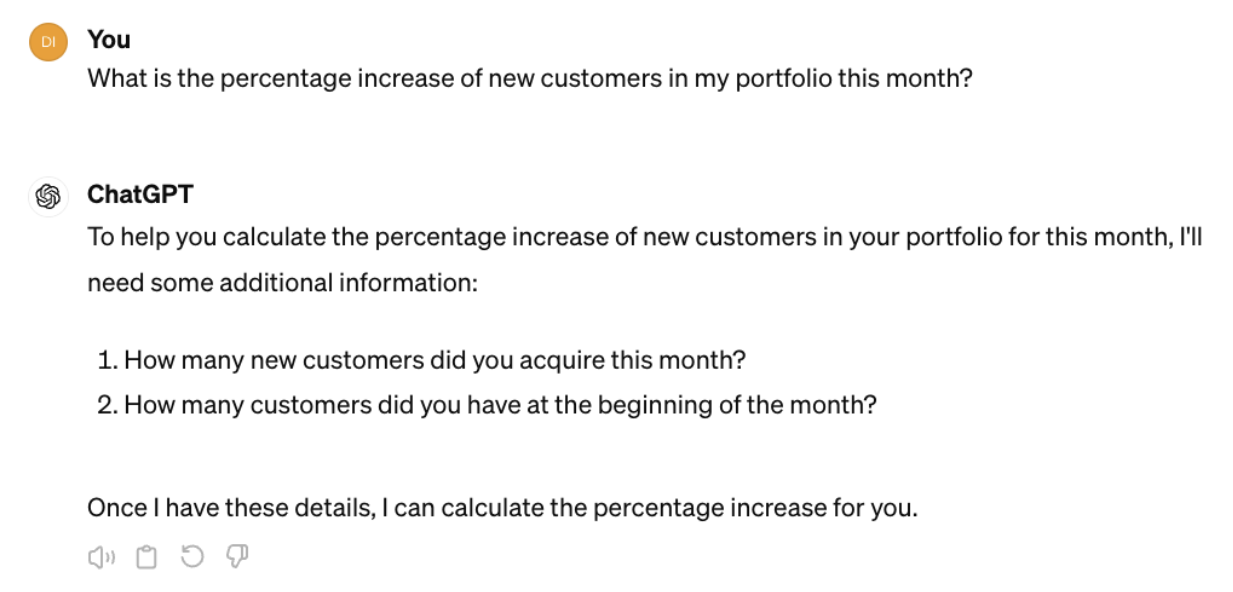
The comparison between programming language and natural language is chosen on purpose. Let us look at the image below. Change one letter in the python code on the left, and it won't work anymore, the computer won't understand what you mean. Change a letter in the prompt that results in the image on the right, and it will still work, even with typos.

Natural language makes it much easier for humans to give instructions: no need to learn programming languages, no need to learn how to work with software... Just ask your computer!
Can we now do everything on our computer through natural language?
Unfortunately generative AI and LLMs are not an universal solution to all our problems, let's look at some limitations. First, the answers from the LLM are non-deterministic. The same prompt could generate different answers, although (hopefully) with the same meaning. Second, language can be ambiguous. A computer might not understand immediately what you want, forcing you to step into a dialogue to clarify your intentions. Third, "P" in ChatGPT, the most famous LLM-powered chatbot, stands for "pre-trained". This means that it won't be capable of responding to prompts using information that was not in its training set. Finally, an LLM is not an all-knowing creature that has access to everything. It won't be able to post a message on your linkedIn, or write you an article and publish it online, at least not by default.
The first two limitations are bound to natural language. It makes it hard to test for example the quality of the output of an LLM. The last two limitations can be overcome by making use of so called "LLM grounding", adding use-case specific information to LLM's that was not used in the initial training, and "LLM agents", combining LLM's with other systems to execute and automate more complex tasks. In this article we'll zoom in on LLM grounding.
RAG to the rescue
Two general approaches exist to make sure large language models "know" about your specific context. The first method to ground AI-systems is by fine-tuning them. This means you extend the training of the model with concrete examples from your organization. After this additional training is done, you will have a unique model that understands the specific situation you trained it on, as well as the broader capabilities it had before. This means that you will only have one component to manage: the model. Nevertheless, you will have to source a high quality dataset with relevant examples, and each time something changes or new information needs to be incorporated, you will need to retrain your model to reflect these changes, which is currently expensive and time consuming.
The second method is called Retrieval Augmented Generation (RAG). RAG is based on in context learning: an LLM can take into account information that was given in the prompt and learn from potential examples before generating answers. This powerful feature allows us to add use-case specific context to the prompt of an LLM when a certain question is asked.
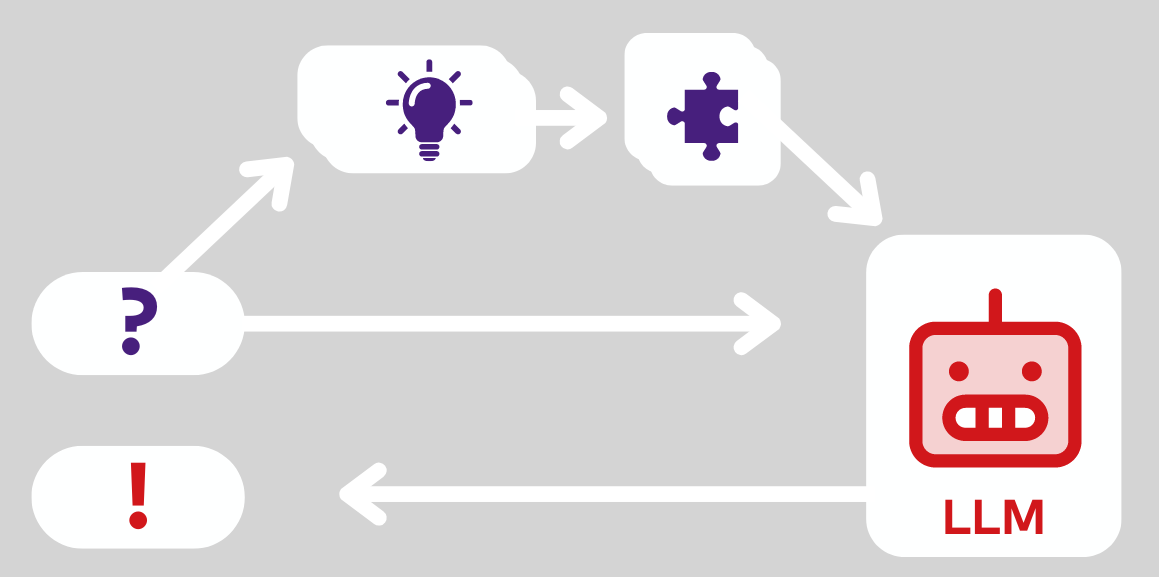
Here is how RAG works (high level):
- The user asks a question
- We find the relevant context to add to the question in the use-case specific knowledge base
- We add relevant context to the prompt
- We let the LLM generate an answer
The RAG setup has some clear benefits over finetuning. First, no expensive training is required. The reason for this is that we do not change anything about the pre-trained model, we just add additional context information whenever a question is asked to the model. This leads to another benefit, we can switch LLM models when we want! Because we are not dependent on any specific model, we can change and test whichever model we like. When GPT-5 or another model becomes available you can just switch out the model you used before for this new one and enjoy its new capabilities.
Currently fine-tuning and RAG are often seen as either one or the other. We recommend to start with a RAG set up and graduatly expand the solution, extend your context with relevant documents step by step. Over time you can build out this application, add additional components, LLM's and technology will evolve, and maybe at some point you can add your own fine-tuned model in the mix.
Getting your chatbot in production
The high level RAG setup is easy to understand, but to make RAG work in a production setting, you'll need to consider several things. First, you need to have a well-documented and validated knowledge base. Inconsistent information will lead to a quality drop of your chatbot. Also, your source information needs to be stored in documents that a computer can interpret, such as text or images. In addition, you need to set up processes to ensure that these documents stay up-to-date, otherwise you risk to feed the model with outdated information.
Besides the knowledge base, you will also need to be able to manage a complex set of components in the RAG pipeline, such as embeddings and vector stores (the components that are used to find relevant context based on the user question).
Each of the choices that you make will have an impact on the quality of your chatbot. It's key to have a framework in place that allows you to measure the impact of your choices on quality, and that allows you to decide when you are ready to go to production
New possibilities in your business
The RAG architecture opens a lot of new opportunities within different business contexts. Think about an assistant for your internal helpdesk, enhanced customer support, automation of administrative tasks that require understanding of specific documents, interpretation of text and images in high volumes, for example in luggage services at airports.
Humans still play a vital role in the setup of such a system, most notably in assuring the quality of the information. Imagine a shift from investing human resources in producing answers and having them focus on setting up the correct processes and maintaining a high-quality knowledge base. This knowledge base would give a machine the needed tools to give correct answers to any number of customers, at any time. By doing so, we can free up time from experts to focus on enhancing the knowledge base and improving data quality.
Rather than investing human resources in producing answers, it's crucial to invest these resources in setting up and maintaining a high-quality knowledge base, as well as validating the quality of RAG outputs. In this way, a machine can provide answers, at any time, to any number of customers, while humans can focus on knowledge and data quality.
How we implemented RAG at our client
We leveraged RAG at one of our clients. Here a chatbot is developed on top of their knowledge base, to support 1000 knowledge workers find relevant information quickly.

Conclusion
The technological evolution brings ever more capabilities to what computers can do. Recently we've developed systems that can process the meaning of text and images. This opens a wide range of possibilities in applying these systems to solve business problems. However teaching them the relevant context of a specific business has been the main challenge in applying these systems to solve real world problems. Currently RAG and fine-tuning are the two go to methods to doing so. Get in touch with us if you want to leverage these new techniques to solve your business problems.
