Tech Review: Tracing Data Lineage from Notebooks into Microsoft Purview


This post is a technical deep dive into some of the topics covered in an earlier Datashift blog, When Data Governance Meets Data Engineering: Optimizing Microsoft Purview with SparkLin for Automated Lineage.
Microsoft Purview has a variety of robust lineage capabilities right out of the box. We recently faced a situation at a client where we did, however, need a custom solution.
In this post, we'll show how to trace data lineage from notebooks in Spark environments into Purview, using OpenLineage and Sparklin. The aim is to discuss how we implemented this solution and how we encountered some unexpected things along the way, so it might be useful for teams working on similar lineage extraction projects.
For a technical introduction to the tools we are using, see:
- The main concepts of OpenLineage's Spark integration
- An overview of the Data Lineage solution on the Microsoft Security Blog
- The README of the PyApacheAtlas repository
Considerations for using the Data Lineage solution
As we'll see in more detail below, OpenLineage emits events in JSON format. The first step in processing these is to capture and store the events relevant to our use case. For that we use a service written in Python, adapted from the Sparklin component of an open source solution called Data Lineage in Microsoft's GitHub organization. However, the Data Lineage repository isn't actively maintained as of posting this blog, with the last commit dating back to December 2023 and several open PRs with no activity. Teams planning to implement this solution in production environments should thus fork and commit to maintaining the code themselves, as we did, with the possibility of eventually contributing improvements back to the open source community.
Architecture overview
OpenLineage's approach for lineage extraction from notebooks depends on Spark, through an implementation of the SparkListener interface. Here, we're using it in Azure Synapse Analytics, but the same concepts apply to other Spark-based platforms such as Azure Databricks and Fabric. This is quite relevant as Fabric further strengthens its position as Microsoft?s flagship analytics platform, meaning, teams could migrate to Fabric without any changes to the core implementation of this lineage setup.
Everything starts with the OpenLineage Spark integration running on a Spark Cluster. OpenLineage's JSON events are picked up by the JSON Receiver service, written in Python and running in Azure Functions. For every event coming from OpenLineage, the JSON Receiver checks events against a predefined list of Spark SQL operations, writing only events pertaining to these operations to Blob Storage for further processing, as well as to Table Storage for driving the execution of the JSON Parser.
For every object written to Blob Storage, the JSON Parser service is triggered, which, like the JSON Receiver, is written in Python and running in Azure Functions. The JSON parser uses the PyApacheAtlas package to read the lineage-related events from the JSON files stored in Blob Storage and then register them as metadata entities in Purview, as well as storing them in Table Storage.
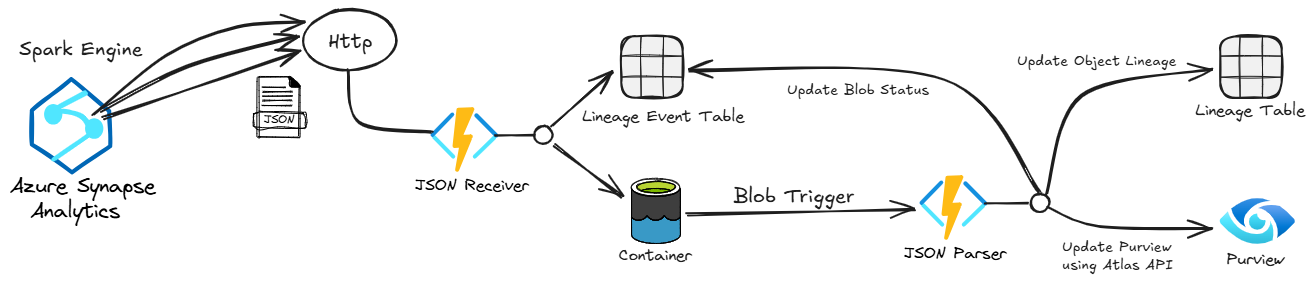
Handling lineage in Purview via the Atlas API
Building custom lineage in Purview requires using the Atlas API, which follows the Apache Atlas standards. As mentioned above, the JSON parser service uses the PyApacheAtlas package to that end. More specifically, it creates metadata entities for each source and sink table with the correct attributes, along with a process entity that links them. This process entity is key for establishing table-level lineage and can also incorporate column-level lineage where applicable. However, some modifications are needed for optimal integration with Purview.
If objects already exist, typically from an automated scan of the data environment, the parser, by default, may create duplicate entities instead of linking to existing ones. Purview assigns both a UUID and a string-based unique identifier called the qualified name to objects. To prevent duplication, the parser must use the same qualified name as Purview. This alignment requires some manual changes to the code to match the architecture of the Data Lake. The best way to test this is by trial and error, and by looking at the different inputs coming from the JSON files.
Another challenge is that the default process type used in the parser does not support column lineage effectively. To address this, the azure_synapse_operation process type should be used, as it enables column-level lineage tracking. These modifications, while necessary, introduce an ongoing maintenance requirement ? ensuring that any updates to the parser continue to align with Purview's metadata model.
Tutorial: sending lineage events to Purview
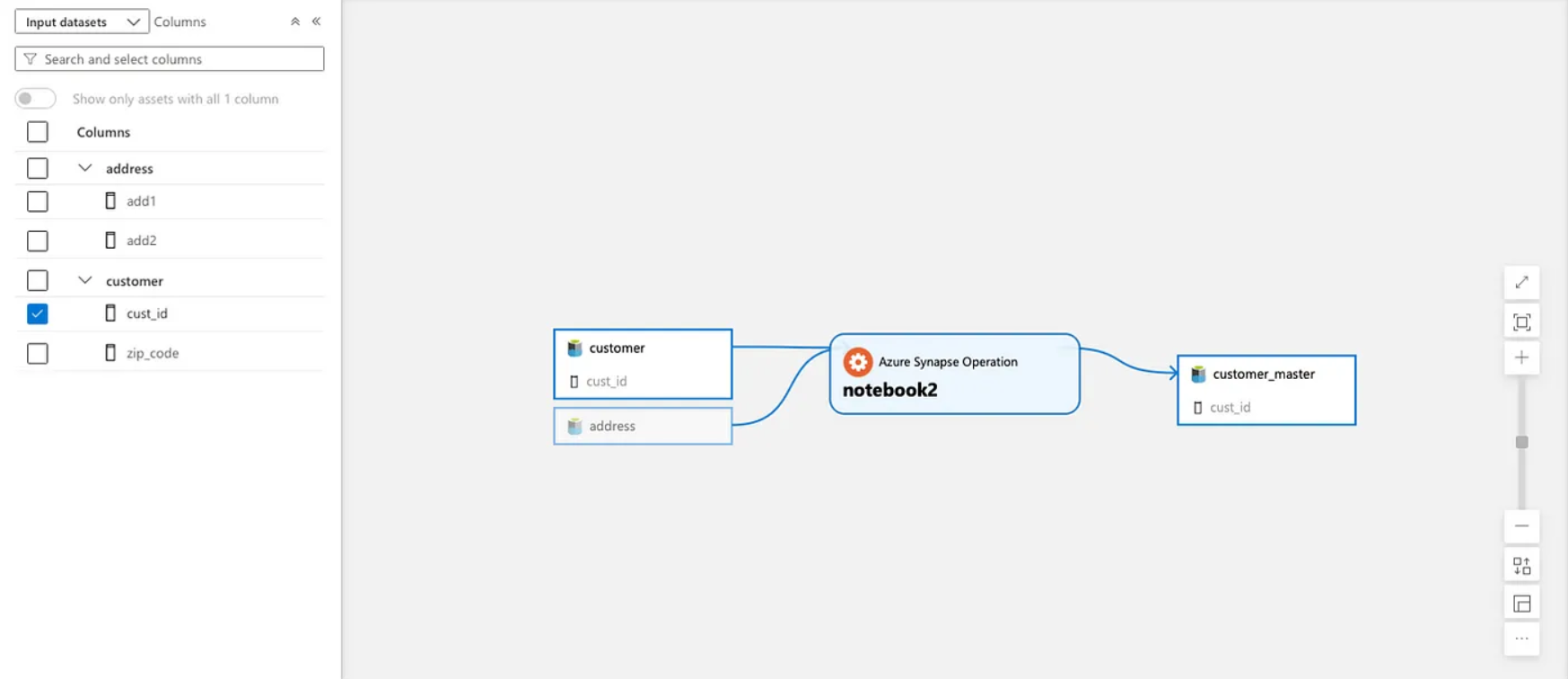
In this tutorial, we will walk through how to send lineage events from JSON data to Purview using the pyapacheatlas package. The example code defines and uploads metadata entities representing data lineage, including tables (source and sink) and a process entity that links them while incorporating column-level lineage
1. Install dependencies
Before running the script, ensure you have installed pyapacheatlas. You can install it using pip.
2. Authenticate with Purview
To interact with Purview, we need to authenticate using Azure Service Principal Authentication. Replace the following values with your own Azure credentials:
- Tenant ID: Your Azure Active Directory (AAD) tenant ID.
- Client ID: The application (service principal) ID.
- Client Secret: The secret key associated with the service principal.
- Purview Account Name: The name of your Purview account.
Security Note: Never hardcode sensitive credentials in your script. Use environment variables or Azure Key Vault.
3. Define metadata entities (source and sink tables)
Now, we define three AtlasEntity objects:
- Two input (source) tables:
customerandaddress - One output (sink) table:
customer_master
Each entity has:
- A name (human-readable name)
- A type name (
azure_datalake_gen2_resource_set) - A qualified name (a unique identifier in Purview)
- A GUID (temporary unique ID for the session)
Why is the GUID negative? Negative GUIDs are used as placeholders during batch uploads. Purview assigns real GUIDs once uploaded.
4. Define column-level lineage
To track column transformations between tables, we use a column mapping structure.
This structure contains:
- DatasetMapping (maps input tables to the output table)
- ColumnMapping (maps specific columns from input to output)
5. Define the process entity (linking the tables)
A Process Entity represents the transformation logic applied to input tables to create the output table.
- The process type used here is
azure_synapse_operationbecause it supports column-level lineage. - The inputs and outputs link the tables together.
We then attach the column mapping information to this process.
6. Upload the entities to Purview
Finally, we upload all entities (source tables, sink table, and process) in a single batch using client.upload_entities().
Why batch upload? Uploading all related entities in one call ensures they are linked correctly in Purview.
7. Verify lineage in Purview
Once the script runs successfully, check Microsoft Purview Studio:
- Navigate to Data Map - Browse Assets
- Search for
customer_master(sink table) - Click on Lineage View to see the transformation from
customerandaddress - Expand column details to verify column-level lineage.
Conclusion
In this post, we showed how to trace data lineage from notebooks into Purview using OpenLineage and Sparklin. We demonstrated the process of capturing and storing lineage events emitted by OpenLineage, and how these events are processed and eventually registered as metadata entities in Purview using the PyApacheAtlas package.
We went over the architecture of the solution, which involves as its main components the OpenLineage Spark integration, and a JSON Receiver and JSON Parser service running in Azure Functions.
Importantly, we discussed the challenge of maintainability when working with open source projects. Given that the Data Lineage repository is not actively maintained as of posting this blog, teams should be prepared to fork and maintain the code themselves, making necessary modifications to ensure compatibility with their specific data environments and in alignment with Purview's metadata model.
If you enjoy diving into challenges like these, why not turn your skills into impact at Datashift? Check out our vacancies.
Keep reading
Eager to learn more? No worries: we’ve got you covered.
.png)
From data chaos to business impact: how to tap into your invisible goldmine
When 90 percent of your information is unstructured, it creates a massive "invisible" friction. It turns daily operations into a series of manual search traps and missed signals, where the more data you collect, the harder it becomes to actually know what is happening inside your own organization.

.png)
The OpenClaw Symptom: Why Your Enterprise AI Strategy is Failing (and what to do about it)
Last month, an open-source AI agent called OpenClaw accumulated 145,000 GitHub stars in weeks. It can book restaurants, manage calendars, and commit code without being asked twice. Researchers have also demonstrated full system compromise via a single malicious email, in under five minutes. We're not suggesting you install it. But the speed at which 145,000 developers rushed toward something that dangerous is worth taking seriously, because it tells you something about the state of enterprise AI that your quarterly review probably doesn't.

.png)
From hidden experiments to confident Gen AI adoption
Employees experiment quietly with AI tools to summarize documents, draft emails, analyze data, or speed up daily work. These initiatives are rarely malicious or careless. On the contrary, they are often driven by curiosity, pressure to deliver faster, or genuine innovation. Yet taken together, these hidden experiments form a pattern that deserves attention: Shadow AI.



