How Hyperscale comes to the rescue when troubleshooting Azure SQL Server performance
22 August 2023

What to do when facing performance issues with your ETL workflows processing data for loading your Data Warehouse in Azure SQL Server? At Datashift, we know from experience that it's not necessarily a matter of spending more to solve such performance issues.
A particular case jumps to my mind where a client noticed that the processing times of the larger and more complex ETL workflows were substantially higher than acceptable. As a result, the data was not being processed in a timely manner for the end-users to have their reports in time. Let’s dive into how we troubleshooted this Azure SQL Server performance issue and how Hyperscale came to the rescue.
Identifying the root cause of the Azure SQL Server performance issue
First, we carefully optimized processing time by rewriting complex database queries, indexing large data tables, and optimizing ETL workflow scheduling, ... until we found that we were achieving only marginal performance gains.
Next, we investigated the standard database monitoring metrics (such as CPU usage, memory capacity, …) to figure out what was causing the long processing times for these complex ETL workflows. While it quickly became apparent that none of those metrics were hitting the database limits, we noticed that the Log IO hit its maximum daily during the ETL processing window. Upon further inspection, we discovered this occurs when hitting the IOPS (input/output operations per second)/throughput limits for the applicable pricing tier.
The query below (provided by Microsoft’s documentation on monitoring Azure SQL database performance using dynamic management views) returned that the wait type 'PAGEIOLATCH_SH' had the highest wait time in our client’s database.
select *
from sys.dm_db_wait_stats
order by wait_time_ms desc;
Having unequivocally confirmed our client was facing an IO issue, we now had 2 options to solve the performance issue:
- Option 1 = Upgrade the database compute size or service tier,
- Option 2 = Identify and tune database queries consuming the most IO.
Upgrading the database service tier
Since we had already rewritten the more complex database queries, identifying and tuning those queries again didn’t seem like the way to go. Therefore, we investigated if upgrading the database service tier could solve the issue. As IOPS/throughput was the bottleneck, we compared IOPS/throughput between the different service tiers for Azure SQL Server using Microsoft’s documentation on resource limits for databases using the vCore purchasing model. Because the Business Critical service tier was out of the picture due to its relatively high costs, we only took the General Purpose and Hyperscale service tiers into account.
While comparing those different service tiers, we noticed that scaling up the General Purpose tier database would increase IOPS only to a limited extent. For example, an upgrade from 24 vCores to 40 vCores (the service tier with the highest available IOPS) would raise IOPS from 7.680 to 12.800. This 66% increase falls short when considering that an upgrade to a Hyperscale tier database with 4 vCores more than doubles IOPS from 7.680 to 16.000, which is higher than the highest available IOPS with the General Purpose tier database.
So, an upgrade to a Hyperscale tier database proved to be the best option to deal with our client’s IO issues. That was all the more true because IOPS increases linearly with the number of vCores when scaling a Hyperscale tier database. Upgrading a Hyperscale tier database from 4 vCores to 18 vCores, for example, would increase IOPS from 16.000 to 72.000.
But what makes a Hyperscale service tier database the best option?
As the upgrade to a Hyperscale tier database decreased the processing window of our customer’s ETL workflows by more than 15%, their data was now processed in time. According to Microsoft's documentation, the Hyperscale service tier is intended for all customers who require higher performance and availability, fast backup and restore, and/or fast storage and compute scalability. But what exactly is the difference with the General Purpose service tier, and what makes a Hyperscale service tier database the best option?
As the figure below illustrates, a standard General Purpose SQL Server architecture is based on two separate layers:
- a compute layer that is running the database engine and is operated by Azure Service Fabric (which initializes processes, controls the health of the nodes, and performs failover to another node if necessary),
- a data (storage) layer with database files stored in Azure Blob storage (which guarantees that no record placed in any database file will be lost). The General Purpose architecture uses so-called "Premium remote storage" as a storage type.
The Hyperscale SQL Server architecture, on the other hand, is a distributed architecture that includes a multi-layer caching system improving both speed and scale.
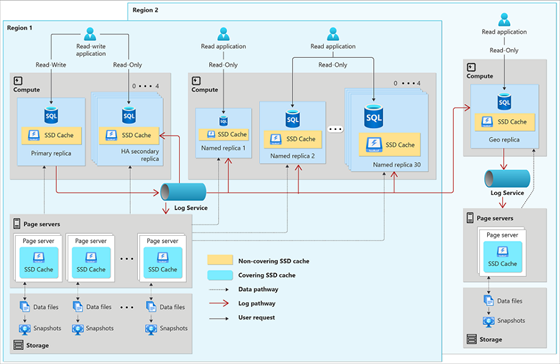
Faster performance is enabled by the compute nodes having local SSD-based caches called RBPEX (Resilient Buffer Pool Extension). These caches allow for low I/O latency for the frequently accessed parts of the database or even the entire database (in the case of smaller databases).
Page servers represent a scaled-out storage engine, with each page server responsible for a subset of pages in the database. Long-term storage of data pages is kept in Azure Storage for durability. The log service accepts transaction log records from the primary compute replica, persists them in a durable cache, and then forwards the log records to the other replicas.
As Hyperscale’s distributed functions architecture provides independently scalable compute and storage resources, it delivers considerable performance and cost efficiency advantages.
Why a Hyperscale service tier database can be the solution for you as well
Based on our findings, here are 3 reasons why a Hyperscale service tier database can be the solution for you as well:
- Higher performance, the Hyperscale service tier being significantly faster than the General Purpose service tier for processing large data sets,
- Better cost efficiency, especially when dealing with long run times due to lower performance (which invoke higher costs when using a General Purpose service tier),
- Easy (reverse) migration from your General Purpose service tier. Thanks to Microsoft’s clear documentation on migrating to and from a Hyperscale database, it’s easy to try out for yourself and see if it can be your preferred solution. If not, you can reverse migrate to your General Purpose service tier. Remember that you need 2 to 4 ETL runs before concluding on processing time because the SQL Server database optimizes its processes internally based on how it’s used.
Want to know more about Hyperscale? Need help implementing Hyperscale to see if it can solve your Azure SQL Server performance issues? Get in touch with us.