Get ready for the future. Meet Azure Synapse.
14 June 2022

In the traditional data warehouse, data from various sources and applications are stored in an SQL database, using powerful ETL tools to prepare the data for analysis. However, such a setup is no longer up to the many data challenges ahead of us. If you want to get ready for the future, regardless of the amount of data you are dealing with, you should check out Azure Synapse.
What’s wrong with a data warehouse?
There's not really anything wrong with a data warehouse. After all, data warehouses have robust reporting and analytics capabilities.
But… with the emergence of IoT data, the use of JSON files, and the increasing importance of image recognition, SQL databases are falling behind. They simply lack the ability to add semi-structured or unstructured data.
In addition, SQL databases combine data storage and processing power in one. Because that does not allow for a cost-optimized setup, there has been an evolution to separate individual data platform components in the cloud
- storing data in a data lake,
- using tools such as Azure Data Factory and Azure Databricks for ETL processing,
- and storing the results in an SQL database that serves as a data warehouse.
And while decoupling data storage and processing is a good thing by itself, it adds significant complexity and unwanted delays because data is copied from one component to another. That’s where Azure Synapse comes into play.
What exactly is Azure Synapse?
Azure Synapse is a big data analytics environment that combines all components of a modern data platform.
Data is stored in a data lake and served directly from it, rather than copying it into a separate SQL database. Furthermore, Azure Synapse has tools for orchestrating data pipelines and processing the data.
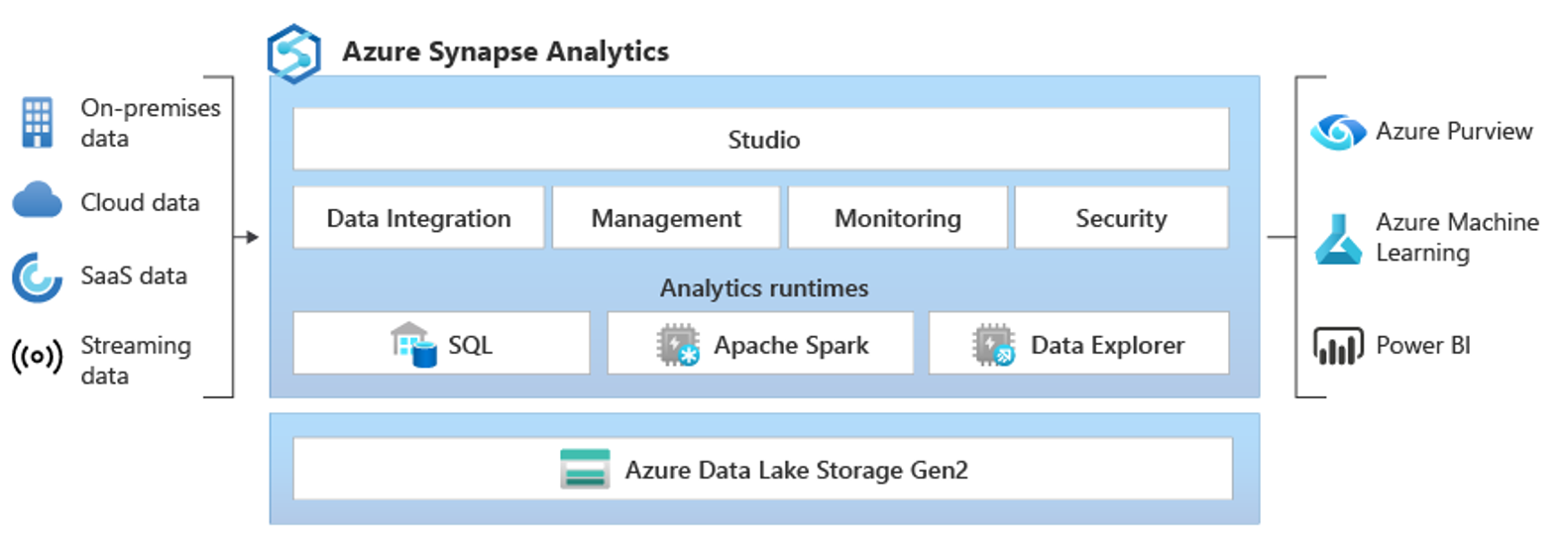
What are the Azure Synapse key components?
Data lake storage
Data lakes enable you to also store semi-structured data such as JSON files or even unstructured data such as images and videos. They provide a cheap data storage solution, especially when your data is stored in the compressed Parquet file format.
With a data lake, you can still model your dimensions and facts, but you store them orderly. Using special data lake patterns, you can clean your data, transform them into dimensions and facts, and build business data sets that can be served straight from the data lake.
Data pipeline orchestration
Azure Synapse’s data pipeline orchestration component controls the execution of all data ingestion and transformation tasks. It provides a no-/low-code solution with many connectors to known source and destination systems.
To transform your data, you can choose between 2 options:
- create and configure a serverless pool of Apache Spark applications. Apache Spark is a parallel processing framework that supports in-memory processing of large volumes of data, boosting performance. Because Apache Spark pools scale easily, they can grow as your data sets get larger over time.
- use building blocks in a visual editor to map data flows and develop data transformation logic without writing code. You can leave the hard work to the building blocks since they produce Apache Spark code behind the scenes.
To serve your data, you can either use a serverless SQL pool or make use of dedicated SQL pools:
- a serverless SQL pool allows you to query any data in the data lake. It’s fast since there is no need to copy or load data into a separate SQL database. And because it's serverless, there is no infrastructure to set up or maintain.
- with dedicated SQL pools, your data is served from an optimized pool of SQL resources. Thanks to the power of the distributed query engine, top-notch performance and availability are guaranteed.
When you combine all this with Azure DevOps services for CI/CD tasks, Azure Synapse enables you to build a genuinely professional data processing framework.
Data analytics
The Azure Data Explorer lets you perform real-time or near-real-time analysis on large volumes of data streaming from applications, websites, machines, or sensors. Its key features include easy data ingestion from multiple sources and straightforward data modeling. Azure Data Explorer replaces the Azure Time Series Insights component, which will no longer be supported from March 2025.
I’m not working with loads of data. Is Azure Synapse for me?
Let’s not beat around the bush: the answer is YES. Even if you don't have billions of records in your database, Azure Synapse is the way to go. Thanks to its pricing model, you only pay for what you use. So it's an excellent approach to start small with the ingestion of the data for one report and transform and serve the data for one dashboard. Then, as Azure Synapse easily scales with your needs, you can grow step by step, adding new data sources or activating Machine Learning capabilities as the need arises.
How does Azure Synapse play with Microsoft’s Intelligent Data Platform?
You might have heard about Microsoft’s Intelligent Data Platform since general availability was announced in May 2022. It consists of (Azure) SQL server, Azure Cosmos DB, Microsoft Purview, Azure AI, Azure Synapse, and Power BI. Microsoft's Intelligent Data Platform brings databases, data analytics, and data governance together under one umbrella.
By looking at all those components from a single perspective, rather than setting individual goals and defining separate roadmaps, Microsoft is paving the way for a unified data platform. And Azure Synapse is a cornerstone of that platform.

Are you eager to hear how Azure Synapse can help you prepare for the future? Reach out to us. We'll be happy to share more in-depth insights.