Is my chatbot ready for production?
22 May 2024

Large Language Model (LLM) applications are everywhere. Most companies are looking to roll out their own chatbot, we see AI-based webscraping tools pop up left and right and some companies are even using LLM's to automate administrative tasks completely. All of this cutting-edge technology, obviously, has the potential for enormous business impact. However, can we prove that our investments in this technology are driving value? When is the performance of these applications "good-enough" to put them in production or do we even know we are going in the right direction? These are all questions that became a little bit harder when we moved away from more traditional machine learning (ML) towards generative AI. Let's have a look at what changed and how we can deal with those new challenges.
Metric-driven development in traditional machine learning
Traditional machine learning, often with a primary focus on regression or classification tasks on tabular datasets, has typically been characterized by metric-driven development. You start of by defining a metric that suits your use-case, for example mean absolute error or accuracy. Then you build a simple baseline model, this could well be an average prediction. After that, the goal of the data scientist is to change components of the data and the model to get the best score on the metric you defined, while maintaining an acceptable level of complexity.
To make sure the model does not just memorize the training-data, data scientists split their dataset in training, validation and test datasets. Comparing the scores obtained on these different dataset-splits tells you a lot about the performance of the model and what you can expect when putting it in production. These metrics give an immediate answer on how accurately the model is performing and whether we're going in the right direction. Therefore, it is straightforward to decide to deploy to production or not. Once the model is in production you need to keep monitoring its performance. When the performance drops below a predefined threshold we need to retrain the model.
Ideally we would like to do the same for generative AI applications, but unfortunately some challenges arise when leveraging this new technology.
Why metric-driven development for generative AI is challenging
Generative AI and more traditional machine learning differ from each other in a few fundamental ways, which have a serious impact on the way we can leverage metric-driven development.
First, generative AI models tend to be trained by external parties, such as OpenAI and Meta, before being utilized by organizations for their specific use-case. This is due to their enormous requirements for data, computing power and energy. For most organizations it's not worth it or even infeasible to train these models, from scratch, themselves. Since models are pre-trained by an external party, we don't have access to the train, validation and test sets in most cases. These general-purpose models get published with their score on some general-purpose benchmarks, but for the most part we lack detailed insights on their performance on the training, validation and test set like we do in traditional ML use-cases.
Secondly, the output of generative AI models is qualitative in nature. This makes it more challenging to directly evaluate them in a quantitative fashion. In traditional machine learning scenarios, you usually aim to predict a specific target, such as a numerical value in regression tasks or a categorical label in classification tasks. Applications leveraging LLMs and generative AI often lack this one-to-one mapping of the answer with the ground-truth value, especially in more complex business problems. This means we cannot just compare the output of the model to some ground truth we have defined and assign it, right or wrong.
Third, applications leveraging generative AI often have a much broader requirement for the outputs that they need to generate. Traditional ML applications are usually tasked with predicting a single output, at best a couple of categories. Generative AI applications like ChatGPT can produce many outputs: you ask it something about finance, about an historical event, or even some advice on what to do when you feel tired after a busy day. Generative AI can generate images, give answer, tell jokes and summarize text. The requirements for these applications are extensive. This means you either need to have a lot of metrics to evaluate different aspects or you need to aggregate everything together. If you do the latter you risk missing important pitfalls, and if you have a lot of metrics it becomes harder to decide which version is indeed the best.
These challenges don't mean the end of metric-driven development for generative AI. However they indicate that we need to do a few things differently. Let's have a look at how we go about setting up a performance evaluation for LLM-driven applications.
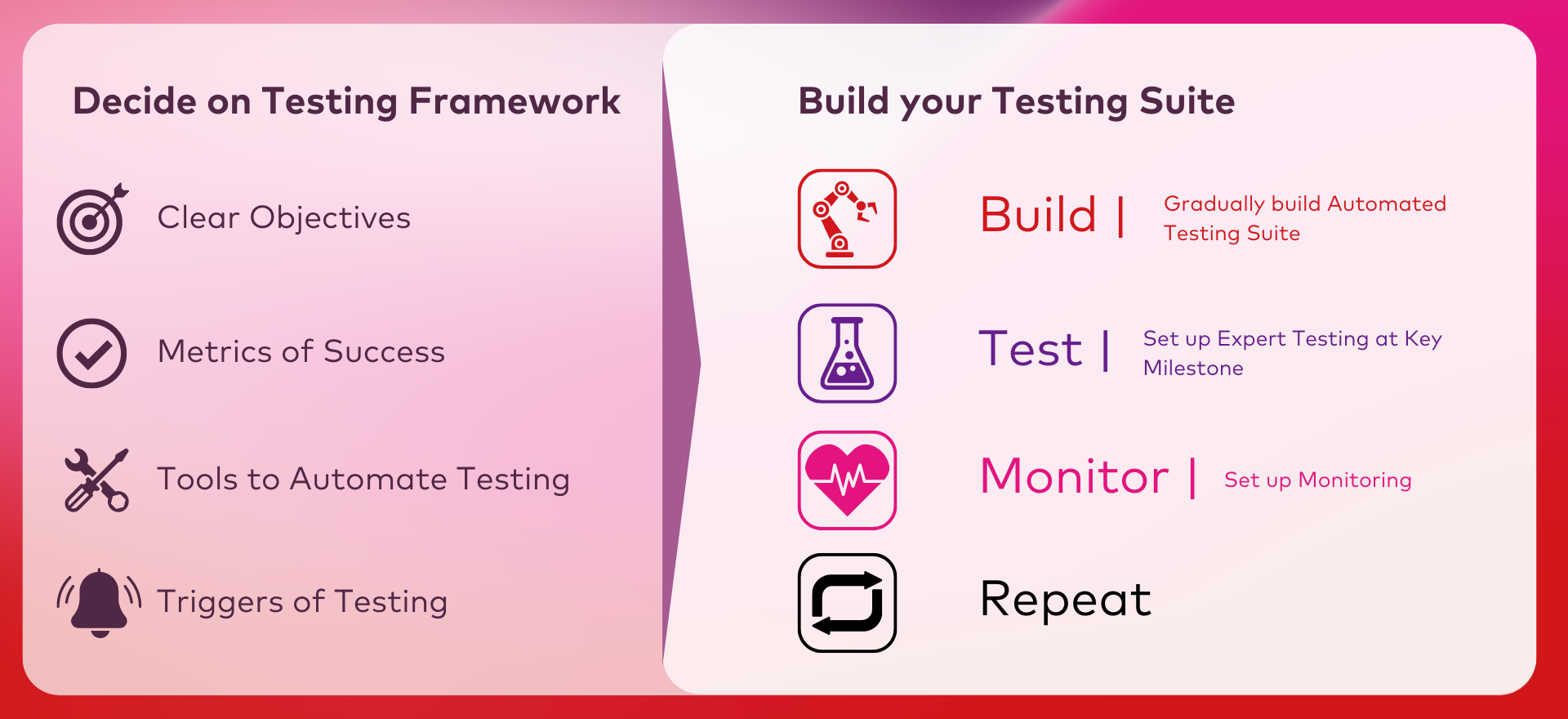
How to set up your test framework?
High level setting up a testing-framework for your LLM-applications consist of two parts. First a shorter planning phase that lays the foundation for the second phase, which is the continuous development of a test suite.
Define your testing requirements and tools
First we need to make some decisions, setting the minimal requirements for the testing of your application. Here we start of by identifying the objectives of the application, what does it aim to accomplish and what is out of scope. From these objectives we can define the metrics we want to use for evaluating our application. Some metrics include the correctness, relevancy and faithfulness of responses but it could also be the precision with which a certain API/tool is triggered or the costs of the application. Once we know how we want to score our application we could look at the tools that could support us in doing so. Some notable mentions are Ragas, modelgauge and the METR task-standard. If we have a good view on what aspects and how we want to score our model we need to define the minimum triggers for actually evaluating our model. We need to decide when to perform the automated testing of the model, when we need to have support of subject matter experts to validate our output and at which point we feel the need for constant monitoring. All of this planning is not set in stone, and you can, and will have to, add or change things in the future. Nevertheless, it's good to have a baseline for the validations that you want to do and have a clear view on the objectives of the project.
Building your testing
The second phase is the development of our testing suite. This is a continual process that will require constant work. Three major blocks can be identified; automated testing, expert testing and monitoring.
Automated testing
Automated testing aims to test new versions of an LLM-application without human intervention. It consists of setting up the tools identified in the planning phase to score the applications defined previously. To set up these tools we'll need to source a test-set. This test set consists of input and their ground truth output. Developers can start with creating the first tests themselves. In addition they can leverage LLMs to build test-cases as well. As soon as we have a version of the test-set and the tools configured we can run this automated testing to score our application on the metrics we set out to do so. The automated testing is often based on LLMs, which may make mistakes that are silly to humans, therefore we should supplement this automated testing with rigorous expert testing.
Expert testing
Expert testing aims to support the automated testing by letting humans review a set of outputs generated by the application. To accomplish this you first need to identify the correct population of experts. Who are the people that could evaluate whether or not the model is helping us achieve our objective. Secondly you need to decide on the method of evaluating that you want to use. You could let the experts evaluate answers on a Likert scale, you could let them rank multiple outputs or you could let them pick the best out of two responses. All of these have their pros and cons. In the end this step is very similar to setting up scientific experiments, requiring planning, people and budget. It's a costly method and it needs a significant time investment. For this reason automated testing should be the first check and only at relevant moments you supplement it with expert testing. In addition you need to make sure that the results and relevant test cases from this expert testing flow back to the automated testing, so they can be automatically verified on next iterations.
Monitoring
Finally, when an application has proven it's value through automated and expert testing, monitoring of your application is advised. Here tracking performance and cost of the application is important. Metrics like time to first token (TTFT) and tokens per minute (TPM) could give you a view on the time it takes to serve users. An average price per user (and the number of users) could give you a view on the cost. In addition, its important to incorporate user-feedback. Give them the option to flag when they found an output useful or not. This is excellent information to add to your automated test set. Also setting up alerting is important either when models become to costly, to slow or even start talking about topics that we do not want them to talk about, we want to be notified so we can take the needed actions.
Maintaining your testing framework
All of this implementation work is an iterative and continuous process, which can lead to making additions or changes to the original plan. Expert testing might show that we need to keep track of additional metrics. The user-feedback might indicate, either implicit or explicit, that we need to shift our objectives. In the end this testing framework aims to get a better understanding of our applications and to gauge whether it's moving in the right direction. The objective of the application, like the language its based on, will change throughout time. Therefore we'll need to continuously need to update both our application and our test-setup.
Conclusion
Generative AI opens a lot of new possibilities. Yet it's difficult to evaluate how well they operate in your specific context. Traditional machine learning applications leverage metric-driven development to iteratively improve the application. Due to the nature of generative AI it's challenging to use the exact same methods to generative AI.
We propose a two step framework to set up your testing-suite, consisting of a planning phase and a continuous development phase. The plan formalizes the objective of the project and decides on the metrics, tools and minimal requirements. The implementation phase focusses on continuously building a set of tests to get a better understanding of the capabilities of the application.
Generative AI brings with it exciting opportunities and complex challenges, these are the reason that spark our enthusiasm. Feel free to reach out if you have any questions or ideas about leveraging AI in your organization.